Start Here
CassIO is designed to power several LLM frameworks. In the following, you will see it in action within one such framework, LangChain. You will run a short question-answering (QA) example, whereby an input corpus of text is first inserted into a Vector Search database index and then, for a given "user question", queried to retrieve the relevant subdocuments and construct an answer to the question.
The quickstart is designed to run out-of-the-box as a notebook in Google Colaboratory ("Colab" for short) and to use Astra DB as the Vector Database.
Other ways to run the code
The following will guide you through running your own QA pipeline in LangChain.
Feel free to look around for other examples and use cases: all you need is a database and access to an LLM provider (as shown through the rest of this page).
If you prefer, however, you can run the very same examples using Jupyter on your machine instead of Colab: only the setup is a bit different. Check the "Further Reading" section for details.
We suggest to use a cloud database on DataStax Astra DB, which currently offers Vector Search capabilities in Public Preview. Should you prefer to run a local Cassandra cluster equipped with that feature, you can definitely do that -- but bear in mind that Vector Search has not made it to official Cassandra releases, hence you'll have to build a pre-release from source code. We'll outline the process in the "Further Reading" section for your convenience.
We'll come to the code in a moment; first, let's check the pre-requisites needed to run the examples.
Vector Database
Create your Vector Database with Astra DB: it's free, quick and easy.
What is Astra DB?
Astra DB is a serverless DBaaS by DataStax, built on Apache Cassandra. It offers a free tier with generous traffic and storage limits. Using Astra DB frees you from the hassle of running your own cluster while retaining all the advantages, such as the excellent data distribution and very high availability that make Cassandra a world-class NoSQL database.
Create the Database
Go to astra.datastax.com and sign up.
Click "Create Database" and make sure to select "Serverless with Vector Search".
In the following we assume you called the database cassio_db.
You will also be asked for a "Keyspace name" when creating the database:
you can call it something like cassio_tutorials for example.
(A keyspace is simply a way to keep related tables grouped together.)
In a couple of minutes your database will be in the "Active" state, as shown in the DB Quickstart page.
Detailed explanations can be found at this page.
Database Access Token
Now you need credentials to connect securely to your database.
On the DB Quickstart panel, locate the "Create a custom token" link and generate a new token with role "Database Administrator". Make sure you safely store all parts of the Token: it will not be shown anymore for security reasons.
Detailed information on DB Tokens can be found here.
Database Secure Connect Bundle
Next, you need a "Secure Connect Bundle" zipfile, containing certificates and routing information for the drivers to properly establish a connection to your database.
On the DB Quickstart panel, find the "Get Bundle" button and click on it. You don't need to unpack the zip file, just save it on you computer: you will need it momentarily.
For more info on the Secure Connect Bundle see this page.
LLM Access
In order to run the quickstart, you should have access to an LLM. You will be asked to provide the appropriate access secrets in order to run the full code example: make sure you have them ready.
The notebooks currently support the following providers for LLMs:
- OpenAI. In this case you will be asked for a valid API Key.
- GCP Vertex AI. In this case you need a JSON API for a Service Account whose permissions include the Vertex AI API.
- Azure OpenAI. In this case you will need several parameters: the base URL to your Azure OpenAI resource, the API version string, an API Key, and the deployment and model name for both the LLM and the embedding models.
See the inserts below for more information on each provider.
OpenAI
Log in with OpenAI (creating an account if you haven't yet).
By visiting the API Keys page in your user account, you will be able to generate an API Key. Make sure to copy it and store it in a safe place.
GCP Vertex AI
In order to use Google's Vertex AI service, you need an account with access to that service.
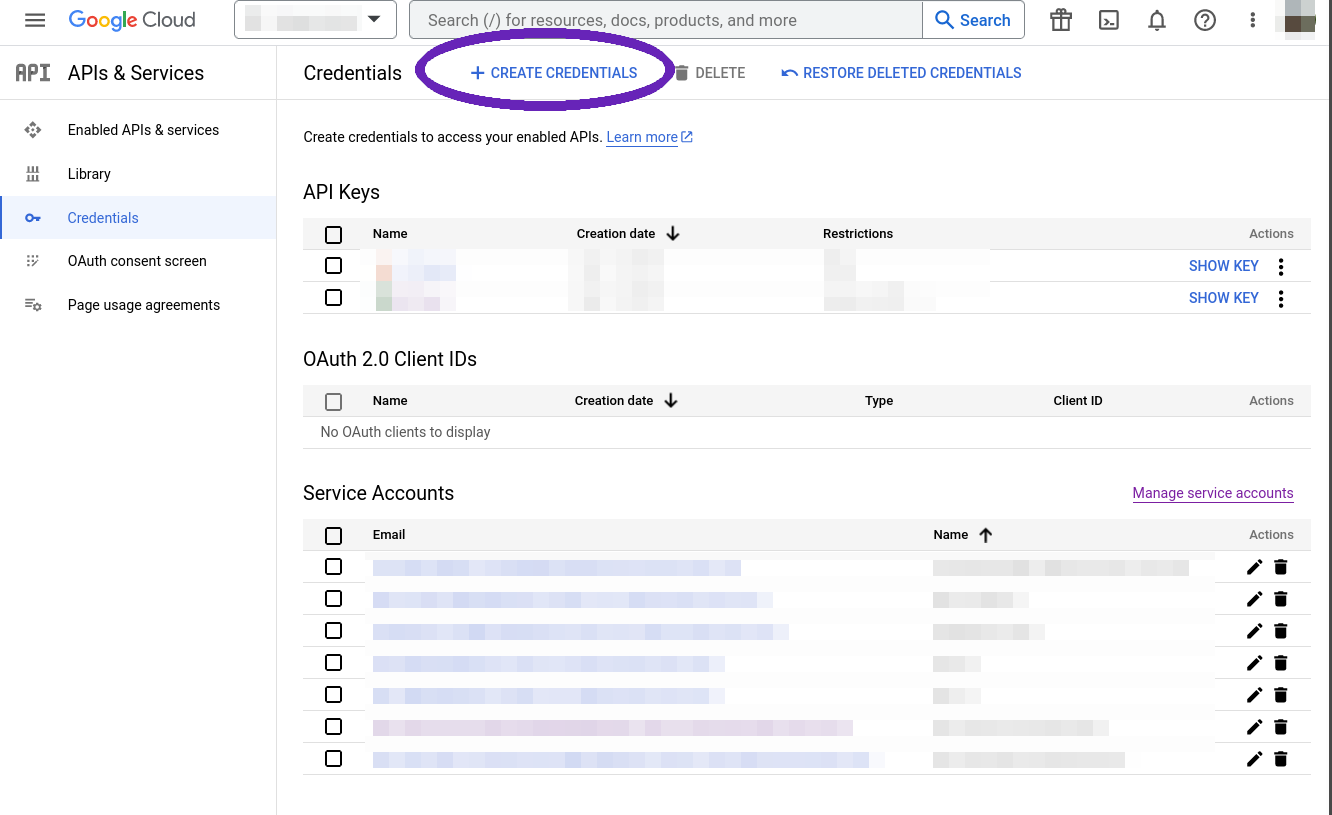
Once you log in, go to the API Credentials Console, make sure the right project is selected, and click "Create Credentials".
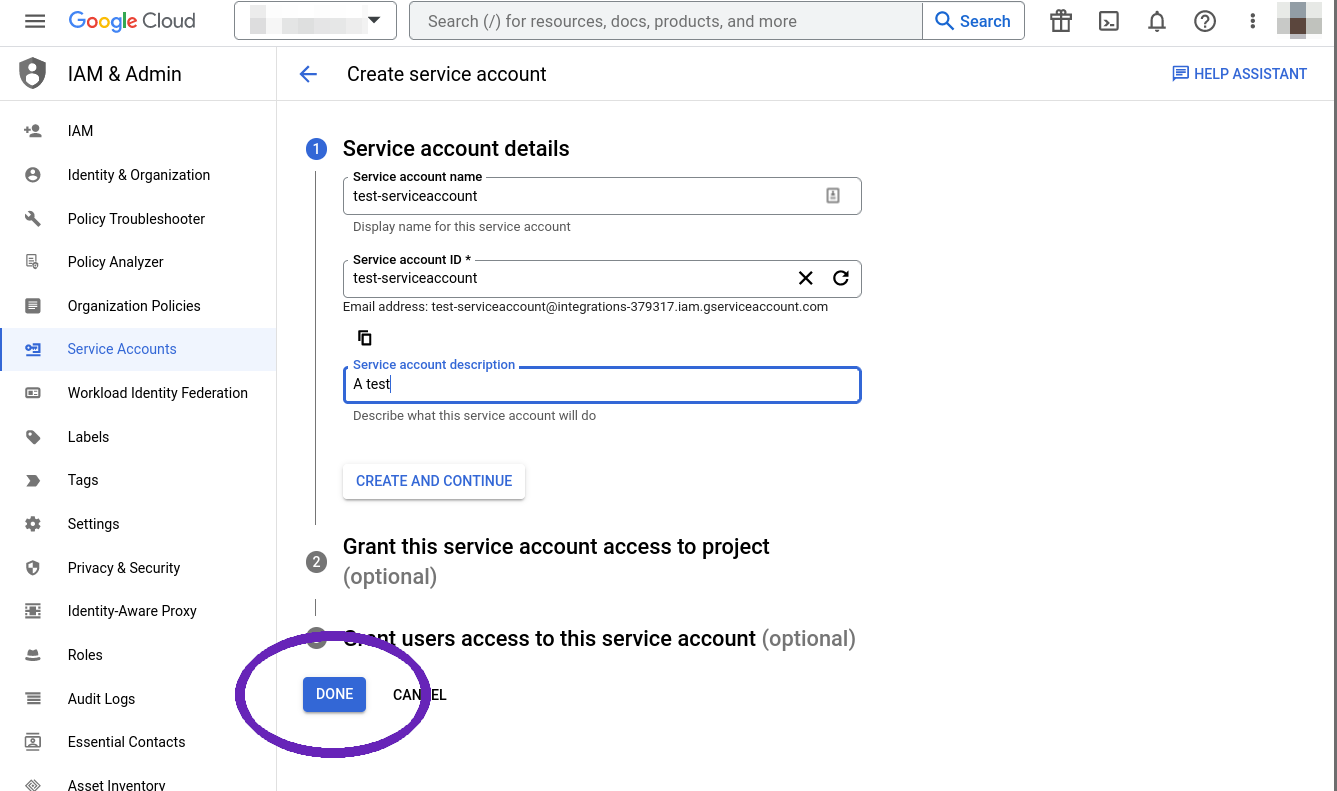
Choose to generate a "Service account" and fill the wizard, then hit "Done".
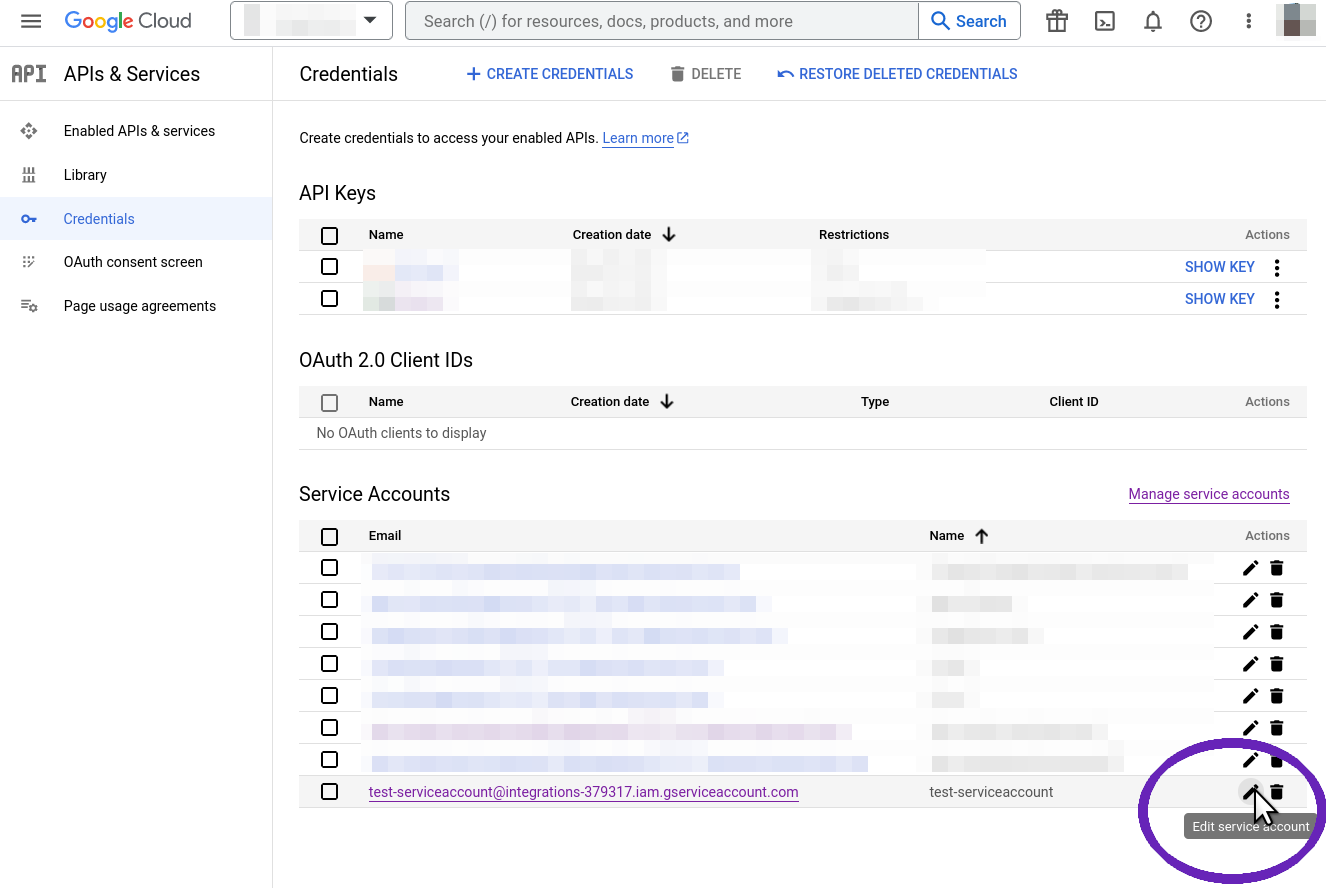
The new service account will be visible in the "Credentials" list. Click the "edit" symbol next to it, then go to the "Keys" tab for this account.
There will be no keys yet: click "Add Key" to create a new one and make it of "JSON" type. You will be prompted to save the JSON key file. Save it on your computer in a safe place, as it will not be made available again.
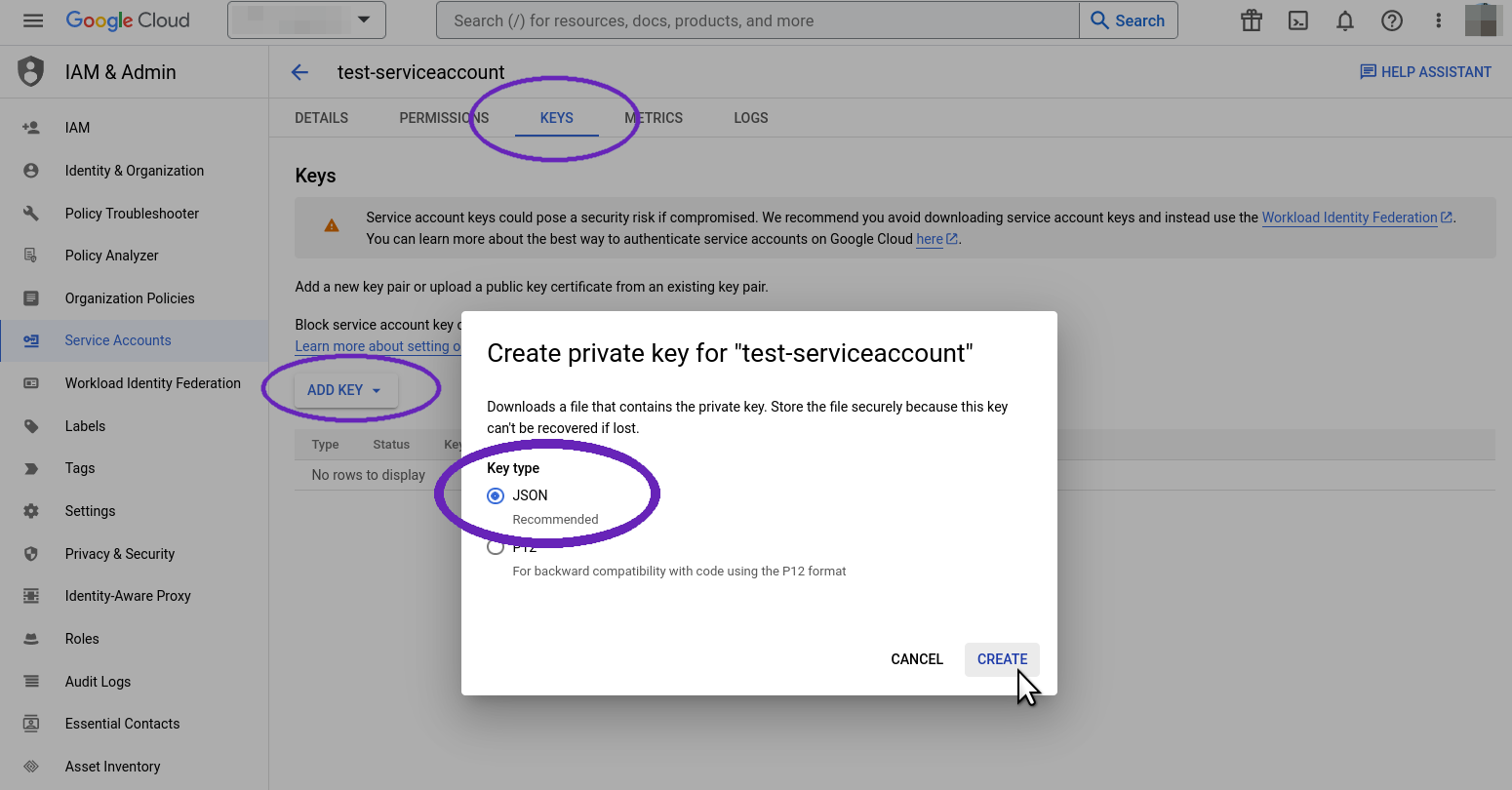
That's it: the full path to the JSON key is the required secret for Vertex AI.
Azure OpenAI
To use LLMs and embedding services from Azure OpenAI, you first need to create a "Resource" in OpenAI Studio and deploy the desired models in it. Next, you retrieve the secrets and connection parameters needed for programmatic API access.
First you need an Azure account allowed to access the Azure OpenAI service.
Log in to the Azure Portal and choose the "Azure OpenAI" service in the dashboard.
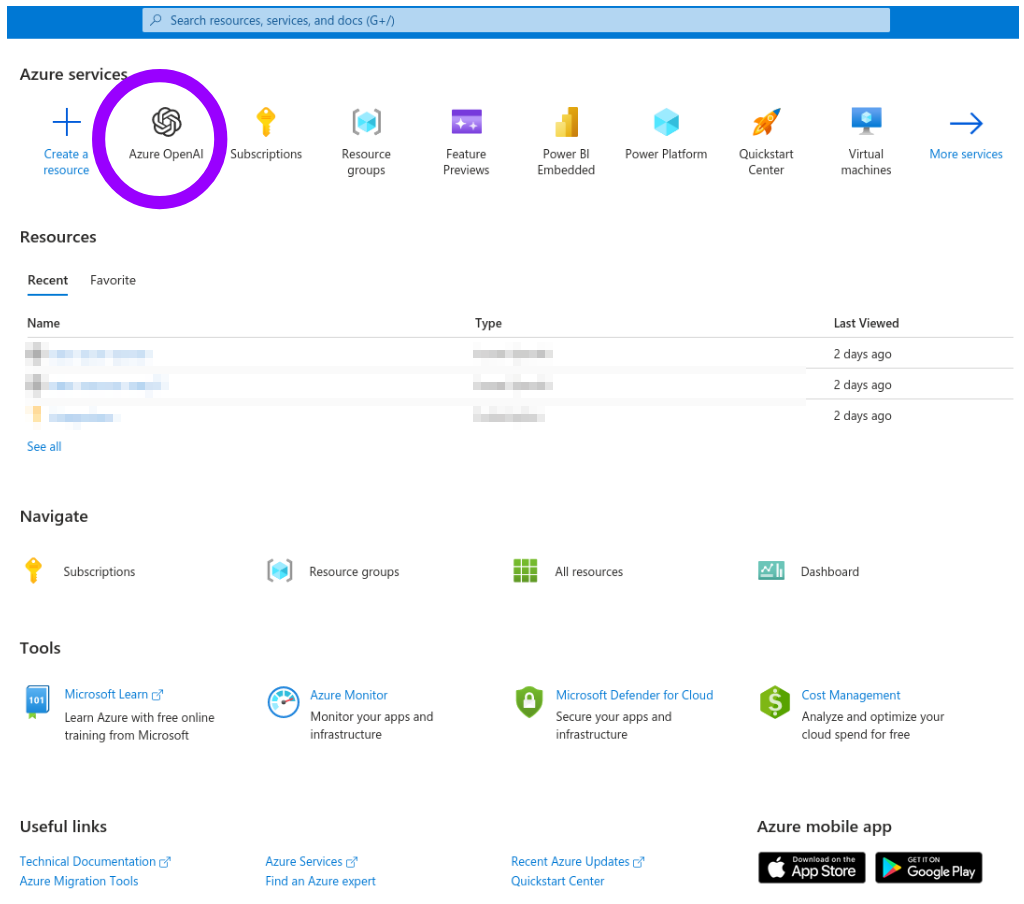
You will see a list of "Resources" (initially empty). Click "Create" and fill the "Create Azure OpenAI" wizard. (You may need to create a "Resource Group" if you don't have one already.)
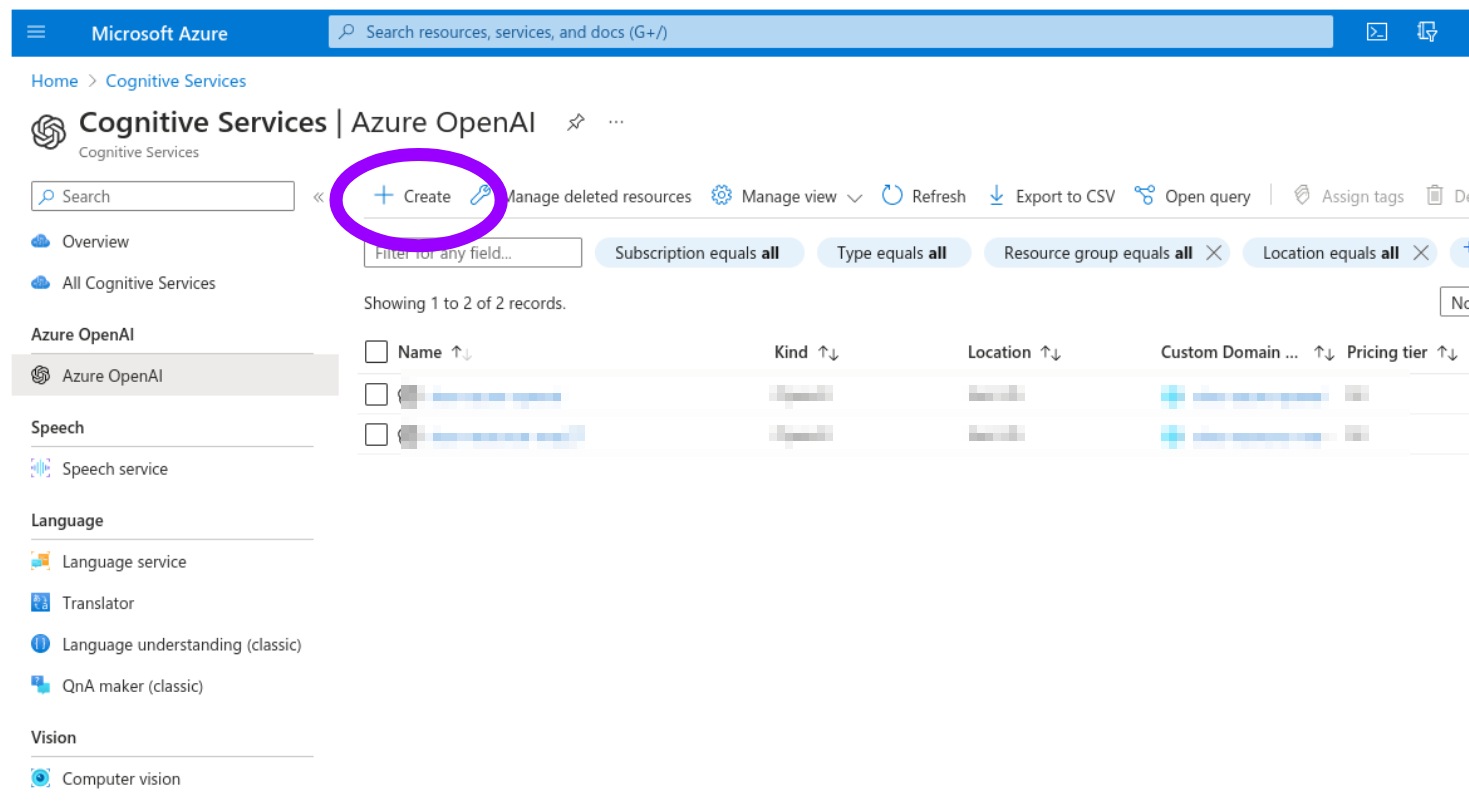
Confirm the process by clicking "Create" at the end of the wizard.
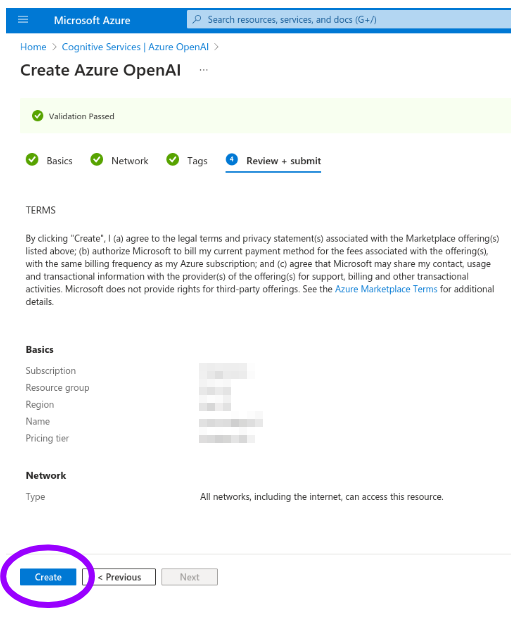
After a few minutes with "Deployment in progress...", you will see "Your deployment is complete". You can click "Go to resource".
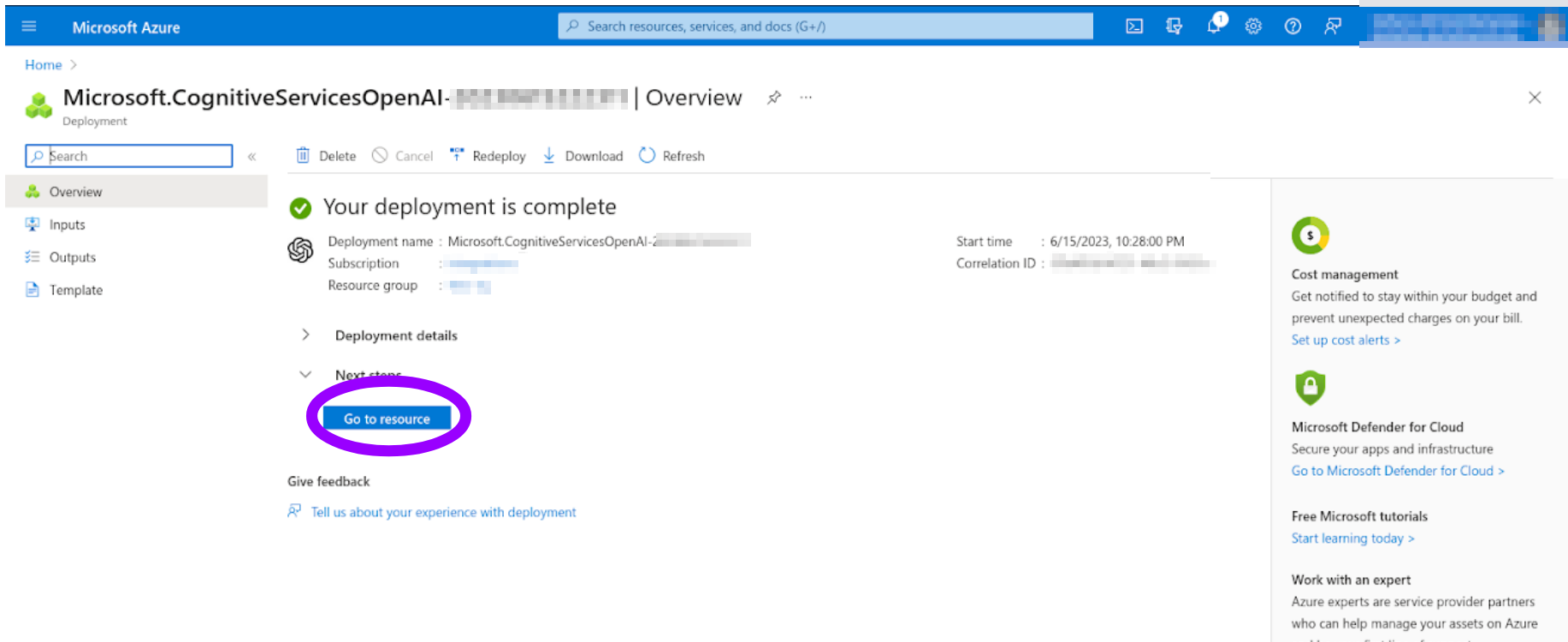
Now, you can "Deploy" a model in your newly-created resource.
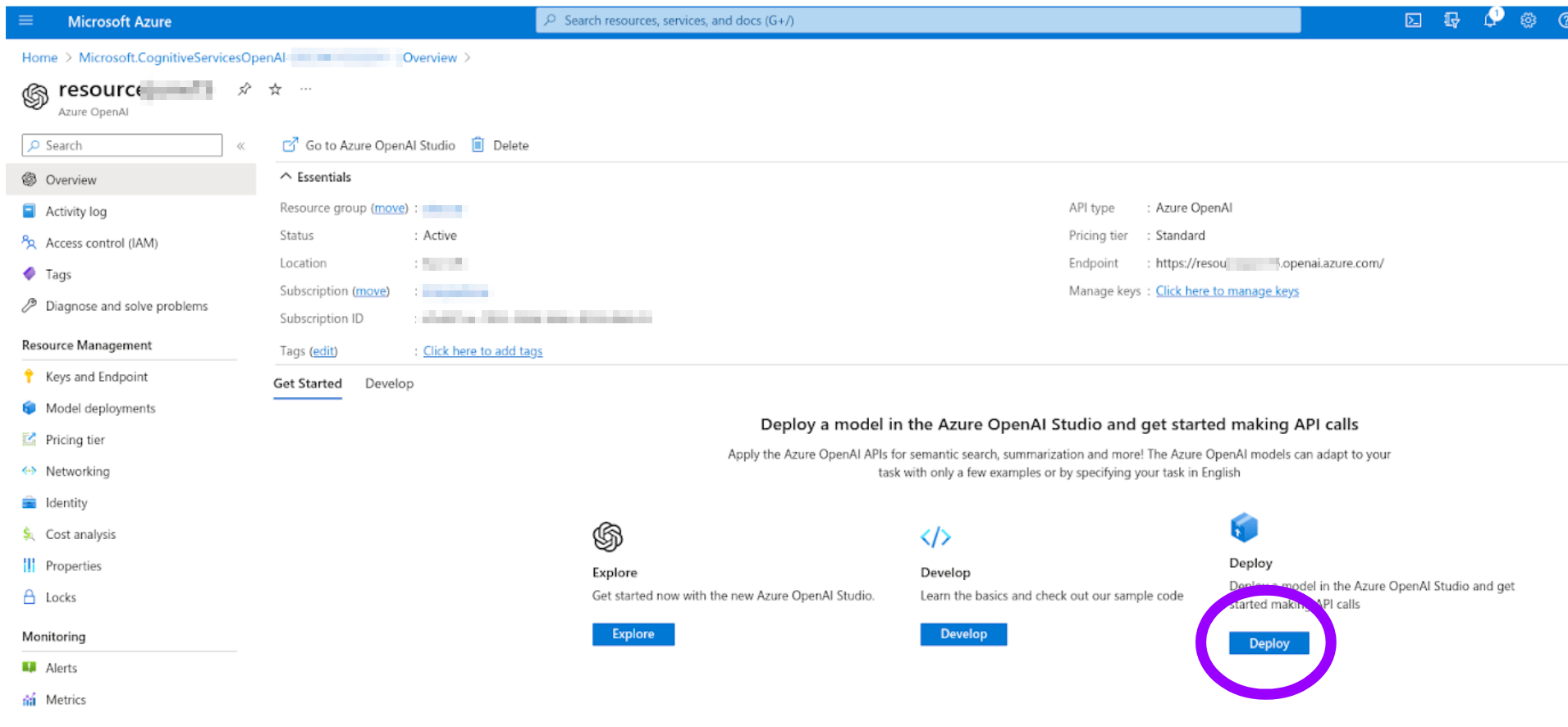
The current deployment list is empty: click "Create new deployment" and pick the model you want. Notice that to have both an LLM and an embedding model you have to do two separate deployments. Take note of the exact deployment name (which you freely choose) and of the model name (chosen from a list), as these will be needed among the connection parameters.
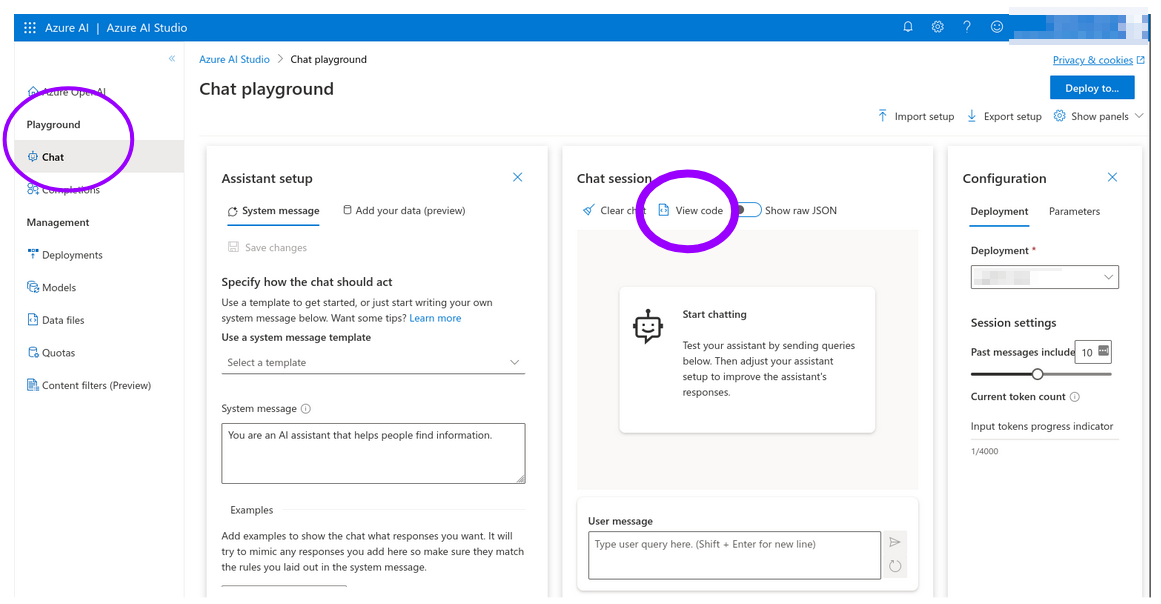
Your models should now be available. To retrieve the connection parameters, start from the Azure OpenAI Studio and click on the "Playground/Chat" item in the left navigation bar.
Locate the "View code" button at the top of the "Chat session" panel and click on it.
A dialog will be shown (make sure that Python code is the selected option), where you will find the remaining connection parameters: the API Version, the "API Base" (an URL to your resource), and the API Key (shown as masked copyable text box).
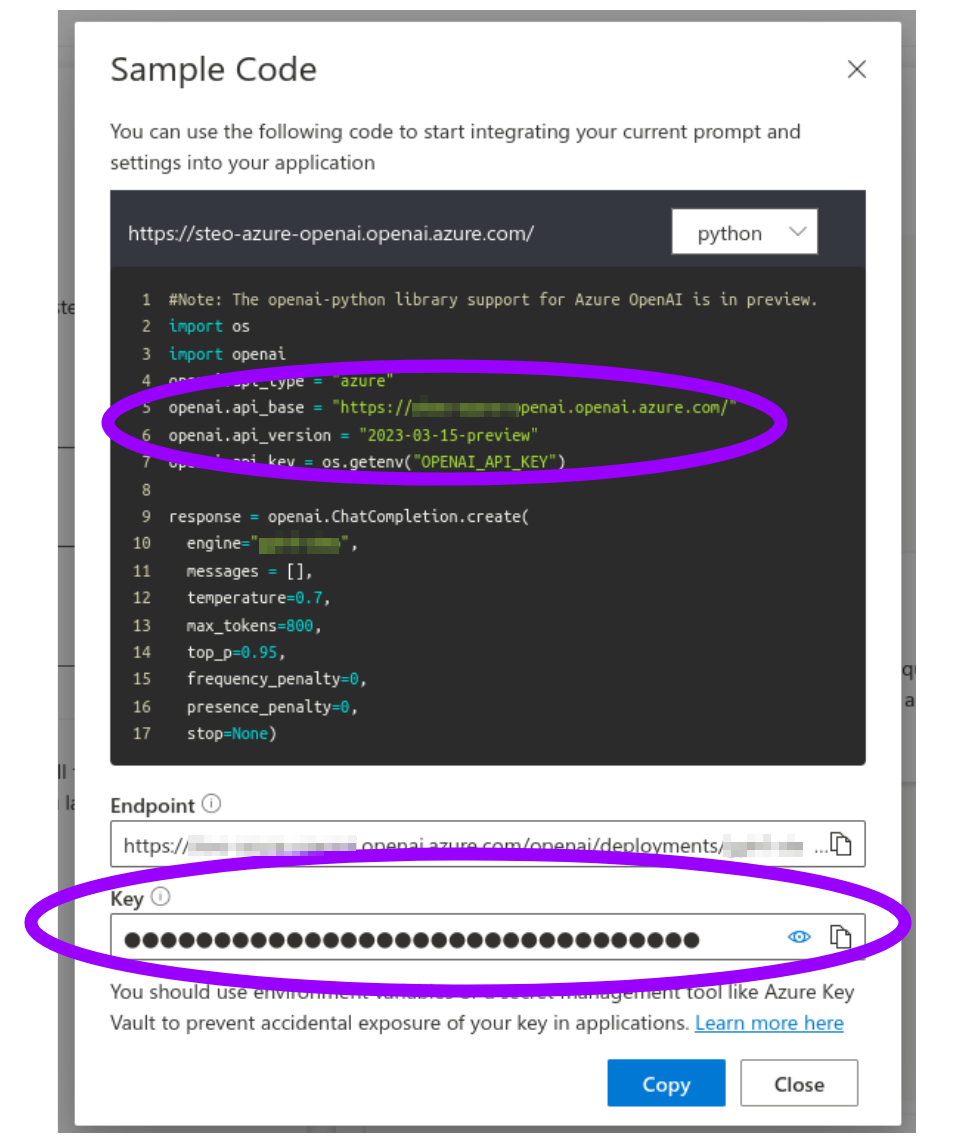
This is it: keep the connection parameters you just collected, as you will have to supply them to run the examples.
Run the quickstart
Once you have the Token and the Secure Connect Bundle, and the secrets required to use an LLM, click on the Colab Notebook link below to start using your Vector Search Database in the LangChain QA example:
![]()
What now?
Now you have first-hand experience on how easily you can power up your application with Vector Search capabilities.
Check out other use cases which benefit from Vector Search, and other ways to enrich your application with LangChain and Cassandra, by browsing the LangChain section of the site.
Look for the Colab
 symbol at the top of most code examples.
symbol at the top of most code examples.
As mentioned at the top of this page, CassIO is designed as a general-usage library: and, sure enough, we will offer integrations with other frameworks, such as Llamaindex or Microsoft Semantic Kernel.
Come back and check again in a few days for more!